Demystifying CNNs: A Technical Guide to Convolutional Neural Networks and Their Application in Medical Image Analysis
In the rapidly evolving landscape of artificial intelligence, Convolutional Neural Networks (CNNs) stand as a monumental innovation, particularly in the realm of computer vision. From recognizing faces on your smartphone to powering self-driving cars, CNNs have redefined how machines 'see' and interpret the visual world. But what exactly are these powerful neural networks, and how do they work their magic? This article will delve into the technical underpinnings of CNNs and illustrate their profound impact through a compelling medical diagnosis study case.
What is a Convolutional Neural Network (CNN)?
At its core, a CNN is a specialized type of artificial neural network designed to process data that has a known grid-like topology, such as image data. Unlike traditional neural networks that treat each pixel as an independent input, CNNs leverage the spatial relationships between pixels. This architecture allows them to automatically and adaptively learn spatial hierarchies of features, ranging from simple edges to complex object parts, directly from the input data.
The Core Innovation: Feature Learning
The key differentiator of CNNs is their ability to perform feature learning. Instead of requiring human engineers to manually design features (like edge detectors or texture descriptors), a CNN learns these features itself during the training process. This capability makes them incredibly powerful and adaptable to a wide range of image recognition tasks, often achieving superhuman performance.
Anatomy of a CNN: Key Layers Explained
A typical CNN architecture is composed of several distinct types of layers, each playing a crucial role in transforming the input data into a meaningful output.
1. Convolutional Layer
This is the heart of a CNN. It performs a convolution operation on the input data, passing a 'filter' or 'kernel' over the image. The filter is a small matrix of learnable parameters (weights) that slides across the width and height of the input. At each position, it computes the dot product between the filter and the input pixels covered by the filter, producing a single output pixel in what's called a 'feature map' or 'activation map'.
- Filters/Kernels: These are essentially small matrices (e.g., 3x3 or 5x5) that act as feature detectors. Different filters can be learned to detect different patterns, such as horizontal edges, vertical edges, specific textures, or corners.
- Strides: This defines the step size the filter takes as it moves across the input. A stride of 1 means the filter moves one pixel at a time, while a stride of 2 would mean it moves two pixels, effectively reducing the spatial dimensions of the output feature map.
- Padding: Often used to add extra pixels (typically zeros) around the border of the input image. This helps to retain spatial information at the edges of the image and control the output size of the feature map, preventing significant shrinkage.
The output of a convolutional layer is a set of feature maps, each highlighting different features present in the original image. Multiple filters are usually applied, creating a stack of these feature maps.
2. Activation Function (ReLU)
Following the convolutional operation, an activation function is applied element-wise to the feature map. The most common choice is the Rectified Linear Unit (ReLU), defined as f(x) = max(0, x). ReLU introduces non-linearity into the network, allowing it to learn more complex patterns that are not simply linear combinations of its inputs. It also helps to mitigate the vanishing gradient problem, which can hinder the training of deep networks.
3. Pooling Layer (Downsampling)
Pooling layers are typically inserted between successive convolutional layers. Their primary role is to reduce the spatial dimensions (width and height) of the feature maps, thereby reducing the number of parameters and computational complexity of the network. This downsampling also helps to make the detected features more robust to slight translations, rotations, or distortions in the input image (known as translation invariance).
- Max Pooling: The most popular type. It takes the maximum value from a small rectangular window (e.g., 2x2 or 3x3) as it slides over the feature map. This retains the most prominent features in that region.
- Average Pooling: Computes the average value within the window. Less commonly used than max pooling but can be effective in certain scenarios.
Pooling effectively summarizes the presence of features in regions of the feature map rather than precise locations.
4. Fully Connected (FC) Layer
After several convolutional and pooling layers have extracted hierarchical features from the input, the high-level features learned by the CNN are flattened into a single, one-dimensional vector. This vector is then fed into one or more fully connected layers, similar to a traditional artificial neural network. Each neuron in an FC layer is connected to all neurons in the previous layer. These layers are responsible for performing the final classification (e.g., 'cat' or 'dog') or regression based on the rich, abstract features learned by the preceding convolutional blocks.
The CNN Architecture: A Typical Flow
A common CNN architecture typically involves stacking multiple blocks of Convolutional-ReLU-Pooling layers. As data flows through these blocks, the network learns increasingly complex and abstract features. The initial layers might detect simple, low-level features like edges and corners. Deeper layers then combine these primitive features to form more intricate patterns like textures, shapes, and eventually, recognizable object parts or even entire objects. Finally, the fully connected layers interpret these high-level, abstract features to make a final prediction or classification.
Meaningful Study Case: Diagnosing Diabetic Retinopathy (DR)
Let's explore a practical and life-saving application of CNNs: the automated diagnosis of Diabetic Retinopathy (DR) from retinal images.
The Challenge: Diabetic Retinopathy
Diabetic Retinopathy is a serious complication of diabetes, causing progressive damage to the tiny blood vessels of the light-sensitive tissue at the back of the eye (the retina). It is a leading cause of preventable blindness worldwide. Early detection and timely treatment are absolutely crucial to prevent vision loss. However, manual screening by expert ophthalmologists is time-consuming, labor-intensive, and requires specialized expertise. This makes it challenging to scale, especially in remote or underserved regions with limited access to medical professionals.
The CNN Solution: Automated DR Screening
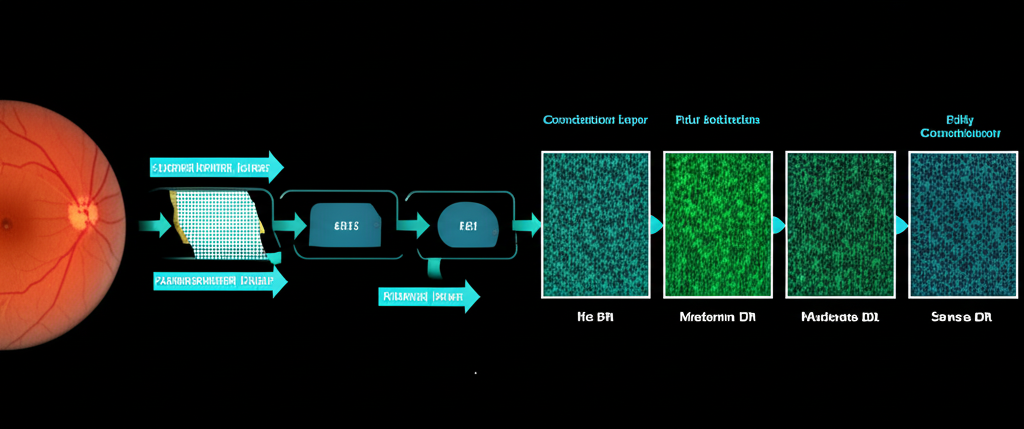
CNNs offer a powerful, scalable, and highly accurate solution to this challenge by automating the analysis of retinal fundus photographs. Here’s how such a system typically works:
1. Data Collection and Preprocessing
A substantial dataset of retinal fundus images is collected from various clinics and populations. Each image is meticulously labeled by expert ophthalmologists, categorizing the presence and severity of DR (e.g., 'no DR', 'mild', 'moderate', 'severe', or 'proliferative DR'). Images undergo preprocessing steps such as resizing to a consistent dimension, normalization of pixel intensities, and sometimes contrast enhancement to highlight subtle features, making them suitable for the CNN.
2. CNN Architecture for DR Detection
A deep CNN is designed or adapted for this specific task. The input to the network is a preprocessed retinal image. The network’s convolutional layers are specifically trained to identify subtle but critical lesions characteristic of DR, such as:
- Microaneurysms: Small, punctate red dots, which are the earliest clinically detectable lesions.
- Hemorrhages: Larger, red blotches or streaks indicating bleeding from damaged vessels.
- Hard Exudates: Yellowish, waxy deposits from leaky blood vessels, often indicative of chronic leakage.
- Cotton Wool Spots: Fuzzy, white patches indicating areas of nerve fiber damage and ischemia (lack of blood flow).
Through successive convolutional and pooling layers, the CNN learns to progressively combine these low-level features (e.g., individual microaneurysms) into higher-level patterns (e.g., clusters of lesions, their distribution, and interaction) that signify the different stages of DR. For example, the presence and density of microaneurysms combined with hemorrhages in a specific region might indicate moderate DR.
3. Training the Network
The CNN is trained on the vast labeled dataset. During training, the network adjusts its thousands or even millions of internal weights (including the parameters of the filters in convolutional layers and the connections in fully connected layers) through an iterative process called backpropagation. Optimization algorithms (like Adam or Stochastic Gradient Descent) are used to minimize the difference between the network's predicted DR severity and the true severity provided by the expert ophthalmologists. The network effectively learns to mimic and often surpass human expert diagnosis by consistently identifying patterns, even those too subtle for the human eye to reliably catch across large volumes of images.
4. Prediction and Impact
Once trained and validated, the CNN can analyze new, unseen retinal images in a matter of seconds, or even milliseconds. It outputs a prediction—for instance, classifying the image as 'No DR' or 'Moderate DR' with a certain probability. This automated screening offers several profound advantages:
- Speed and Efficiency: Rapid analysis allows for mass screening programs, drastically reducing the burden on specialists and wait times for patients.
- Consistency and Objectivity: Eliminates human fatigue, subjective interpretation, and inter-observer variability, leading to more consistent and objective diagnoses.
- Accessibility: Can be deployed in primary care settings or remote clinics, enabling screening where ophthalmologists are scarce, facilitating earlier intervention and better outcomes globally.
- Early Detection: The ability of CNNs to detect subtle signs of DR, sometimes even before they are evident to the untrained eye, is crucial for prompt treatment and prevention of irreversible blindness.
Conclusion
Convolutional Neural Networks have not only revolutionized the field of computer vision by providing an elegant and powerful mechanism for machines to learn complex features directly from visual data, but they are also profoundly impacting critical real-world domains. As demonstrated by the diagnosis of Diabetic Retinopathy, CNNs are not just theoretical constructs but practical tools that are making a tangible, life-saving impact in healthcare, improving efficiency, accuracy, and accessibility. As research continues to advance, we can expect CNNs to play an even greater role in shaping our visual world, from enhancing our daily lives to solving some of humanity's most pressing challenges.